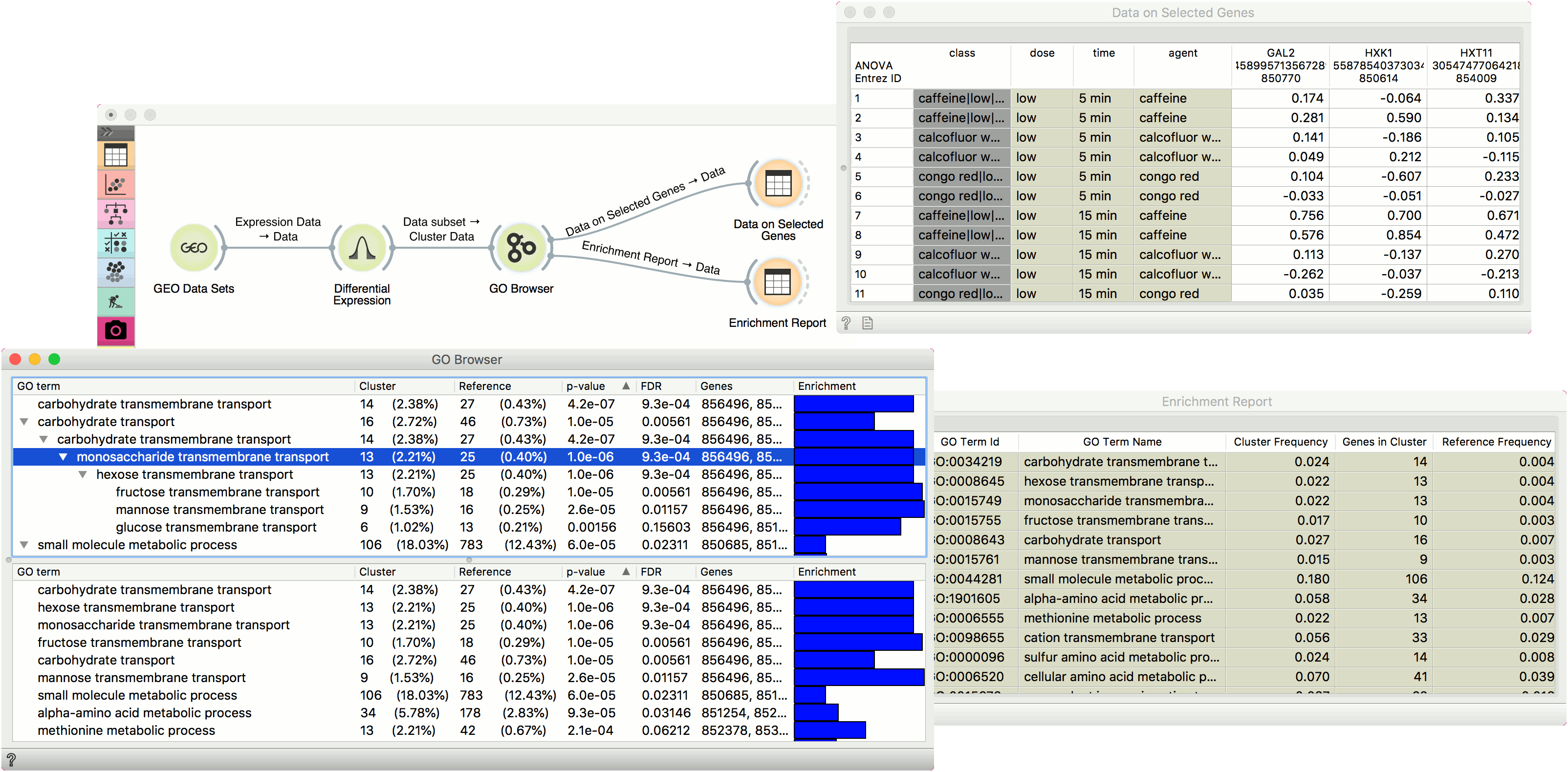
GO Browser
Provides access to Gene Ontology database.
Inputs
- Cluster Data: Data on clustered genes.
- Reference Data: Data with genes for the reference set (optional).
Outputs
- Data on Selected Genes: Data on genes from the selected GO node.
- Enrichment Report: Data on GO enrichment analysis.
GO Browser widget provides access to Gene Ontology database. Gene Ontology (GO) classifies genes and gene products to terms organized in a graph structure called an ontology. The widget takes any data on genes as an input (it is best to input statistically significant genes, for example from the output of the Differential Expression widget) and shows a ranked list of GO terms with p-values. This is a great tool for finding biological processes that are over- or under-represented in a particular gene set. The user can filter input data by selecting terms in a list.
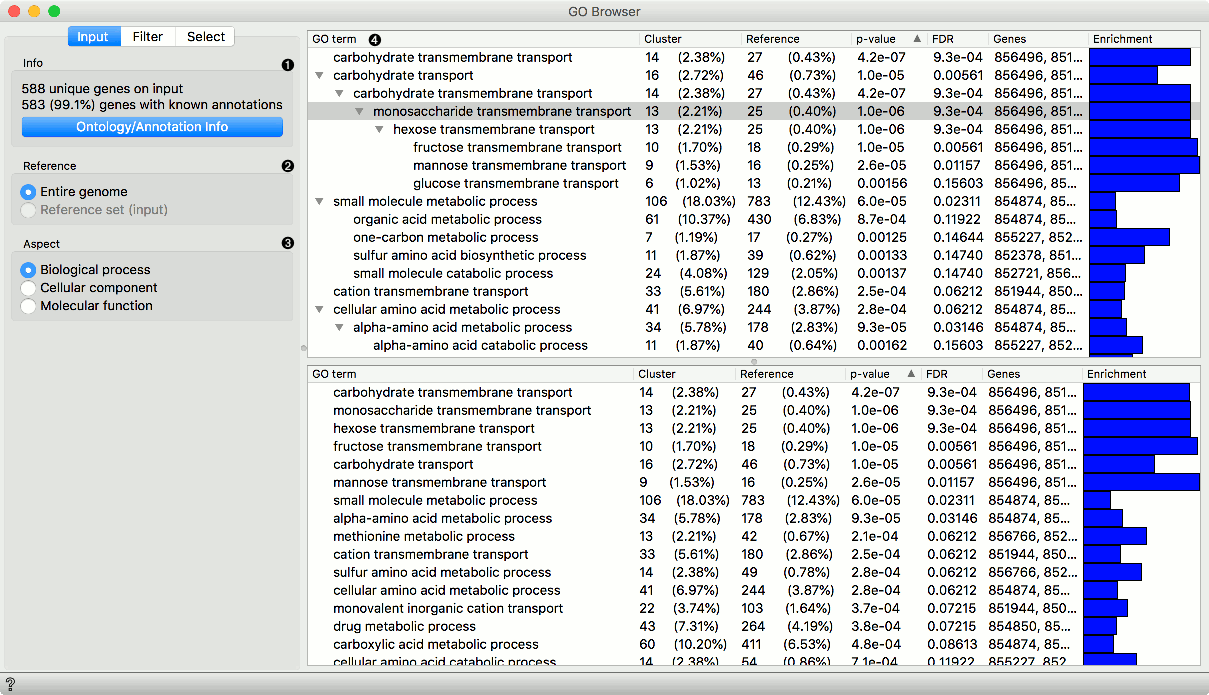
INPUT tab
-
Information on the input data set. Ontology/Annotation Info reports the current status of the GO database.
-
Select the reference. You can either have the entire genome as reference or a reference set from the input.
-
Select the ontology where you want to calculate the enrichment. There are three Aspect options:
-
A ranked tree (upper pane) and list (lower pane) of GO terms for the selected aspect:
- GO term
- Cluster: number of genes from the input that are also annotated to a particular GO term (and its proportion in all the genes from that term).
- Reference: number of genes that are annotated to a particular GO term (and its proportion in the entire genome).
- P-value: probability of seeing as many or more genes at random. The closer the p-value is to zero, the more significant a particular GO term is. Value is written in e notation).
- FDR: false discovery rate - a multiple testing correction that means a proportion of false discoveries among all discoveries up to that FDR value.
- Genes: genes in a biological process.
- Enrichment level

FILTER tab
-
Filter GO Term Nodes by:
- Genes is a minimal number of genes mapped to a term
- P-value is a max term p-value
- FDR: is a max term false discovery rate
-
Significance test specifies distribution to use for null hypothesis:
- Binomial: use a binomial distribution
- Hypergeometric: use a hypergeometric distribution
-
Evidence codes in annotation show how the annotation to a particular term is supported.
SELECT tab
-
Annotated genes outputs genes that are:
- Directly or Indirectly annotated (direct and inherited annotations)
- Directly annotated (inherited annotations won't be in the output)
-
Output:
- All selected genes: outputs genes annotated to all selected GO terms
- Term-specific genes: outputs genes that appear in only one of selected GO terms
- Common term genes: outputs genes common to all selected GO terms
- Add GO Term as class: adds GO terms as class attribute
Example
In the example below we have used GEO Data Sets widget, in which we have selected Caffeine effects: time course and dose response data set, and connected it to a Differential Expression. Differential analysis allows us to select genes with the highest statistical relevance (we used ANOVA scoring and agent label) and feed them to GO Browser. This widget lists four biological processes for our selected genes. Say we are interested in finding out more about monosaccharide transmembrane transport as this term has a high enrichment rate. To learn more about which genes are annotated to this GO term, select it in the view and observe the results in a Data Table, where we see all the genes participating in this process listed. The other output of GO Browser widget is enrichment report, which we observe in the second Data Table.